I'll leave this site up at least until I get all the posts here moved to the new site and probably longer than that. I hope you'll visit the Irreal blog at its new home.
Tuesday, April 26, 2011
Moving Day
I'm moving the Irreal blog to my new Web site at irreal.org. I like Blogger and have been happy with it but I want to host the blog under my own domain and since I'll be using WordPress my work flow will be easier because I can use org2blog to post directly from Emacs.
Saturday, April 23, 2011
Supreme Court Briefs Before Technology Took Over
In view of my post about writing theses before TeX, this article in Forbes by Ben Kerschberg on Remembering The Magic of Supreme Court Briefs Before Technology Took Over really resonated with me. Kerschberg remembers what it was like preparing briefs for the Supreme Court in the “old days” of 1995. In those times, briefs were still printed using hot-metal typesetting, an expensive and time consuming process. Although Kerschberg doesn't mention it, the Court had its own hot-metal press that they used to print opinions and even memos between the justices.
Kerschberg describes going to the printers when briefs came off the press to proof them. They always dressed casually because the proofs were still wet from the ink and they invariably got the ink all over themselves. As with the technical typing I described in my post, errors were extremely expensive because a single typo would mean that a whole line or even paragraph would have to be reset and reprinted. This, in turn, meant they would have to be reproofed for any additional errors that got introduced.
The article is interesting and worth a read. It's another reminder of how much technology has made our lives better. It's easy to bemoan the loss of the beautiful printing that hot-metal presses produced but no one misses the extra work it resulted in, even for those not involved with the printing itself.
First Draft of R7RS For The Small Language
As I recounted in my Two Schemes post, the Scheme Steering Committee decided to split Scheme into large and small languages and formed working groups for each. The small language working group has just published their draft R7RS for the small language. I've read over the draft and am very pleased with it. At 67 pages it remains small and concise and, in fact, it retains the flavor of R5RS as promised.
So what's different? There's a complete list of changes at the end of the draft, and also in the post announcing the draft, but here are some that appealed to me:
- Modules are now part of the language definition. This is important because it was one of the major sources of incompatibilities between different implementations.
- Records à la SRFI 9 are now included as part of the language.
- Parameters, sort of like dynamic variables from Common Lisp, are
introduced as global variables that can be safely dynamically
rebound. Objects such as
current-input-port,current-output-port, and the newly introducedcurrent-error-portare defined as parameters. - Blobs, homogeneous vectors of integers in the range [0..255], are a new disjoint type. This is to allow Scheme to better handle binary data. Ports can now be defined as character or binary.
letrec*is now part of the language and internal defines are specified in terms of it.casenow supports a ‘=>’ syntax analogous tocond's.case-lambdais now part of the base library as a way of dispatching on the number of arguments.string-map,string-for-each,vector-map, andvector-for-eachround out the sequence operations.- Character escaping in strings is expanded.
- Case folding in the reader is configurable with no folding as the
default. Generally I don't care about this because I alway use lower
case anyway and don't understand why anyone would do otherwise. As
an Emacs user I already do enough chording without worrying about
capital letters. Still, it does raise an issue: as soon as Louis
Reasoner sees that case matters he starts using really ugly camel
case identifiers like
GeeIWishIWereCodingTheWindowsKernel. Now Louis is welcome to do whatever he likes as long as I can ignore it, which I can if there is case folding. Of course, once Louis gets used to case mattering, we get stuff like(define sum-odds (lambda (lst) (define SUM-ODDS (lambda (lst result) (if (null? lst) result (if (odd? (car lst)) (SUM-ODDS (cdr lst) (+ (car lst) result)) (SUM-ODDS (cdr lst) result))))) (SUM-ODDS lst 0)))
Mostly, I just wish this issue would magically go away. Or better yet that people would be sensible in their coding conventions.
- No Unicode support is required but the set of characters used by an implementation are required to be consistent with the latest Unicode standard to the extent that the implementation supports Unicode.
Most of this is already in R6RS—indeed, what isn't in R6RS—and almost all of it can be added by the user. For example, we've all written code like
(define string-map (lambda (f str) (list->string (map f (string->list str)))))
as a quick and dirty string-map but now we have a, presumably, more
robust version that handles multiple strings. Even the reference
implementation of parameters can be done at the user level—this is,
after all, one of the strengths of Scheme. What's nice is not a lot of
the work is done for us—well, OK, that is nice—but that these
things are now standardized and portable. There's more than I've
mentioned here so be sure to checkout the draft itself or at least the
list of changes from R5RS.
I'm looking forward to the large language R7RS draft. It will be interesting to see if the working group does indeed manage to produce the “happier outcome” that the steering committee promised.
Monday, April 18, 2011
More on Passwords
The other day, I saw this little piece of fluff positing that passwords such as “this is fun” are more secure than passwords such as, say, “j4fS<2” because they're longer and easier to remember. In fact, the author says that “this is fun” is 10 times more secure than “j4fS<2”. There's a lot wrong with this article and I was going to blog about it but Troy Hunt beat me to it with this excellent post.
There's a lot of confusion and, let's face it, just plain cluelessness about choosing safe passwords so it's good to have articles like this one shed some light on the matter. As it turns out, Hunt has written a series of posts on passwords all of which you can see here. I urge you to read these; the examples he gives of banks, airlines, and others using horribly insecure password policies will take your breath away. Think I'm exaggerating? How about ING using a 4 digit pin as a password for online banking? There are plenty of others too.
Hunt was rightly puzzled by all this so he decided to query some of the worst offenders as to the reasons for their policies. He describes his results in The 3 reasons you're forced into creating weak passwords. I won't ruin the surprise answers that came back—you should read them yourself. Of course, the answers are sadly all too predictable for there to be much surprise but you should still read them.
It's not all fun and games, though. There's a lot of useful information in these posts. For example, I didn't realize that passwords over 14 characters are essentially safe from rainbow table attacks. In view of that, I'm considering having my password generator output 15 characters instead of 10.
Saturday, April 16, 2011
Lisp Is Not An Acceptable Java
Today (April 16) on the Lisp reddit I saw a link to Lisp Is Not An Acceptable Java, a post that repeats every known myth and piece of misinformation about Lisp. Even the title is snort-worthy. After reading the post and shaking my head sadly, I moved on to other things but my mind kept jumping back to the article and I thought that, really, this shouldn't go unanswered. So I got all fired up to give it a good Fisking. But when I read it again, I thought, “this guy is obviously a troll and shouldn't be fed.” Then I noticed that the date on the post was 2011-04-01. OK, an April fools' joke and a good one. The author, Matthias Benkard, is, of course, a Lisper.
What's sad about this is that it works so well. The attitudes and misinformed opinions that the Benkard parodied are common and you do see them expressed all the time. Just last week I blogged about LispWorks' article Common Lisp—Myths and Legends, which was written to rebut the very things that Benkard was satirizing.
I'm not sure what to do about all this. Nobody, it seems, is. All we
can do is smack down gently correct those who repeat these
misconceptions and hope that the meme of Lisp's irrelevance and
manifest shortcomings is not too firmly established to be destroyed.
UTF-8
We all know what UTF-8 is—sort of. It's a character encoding that vastly expands the number of available characters (to 221 characters) yet is still compatible with ASCII. This is a good trick and I occasionally wondered how it worked. I tried reading Pike and Thompson's paper about it when they first introduced it in Plan 9 but while the paper is good on history and “whys,” it doesn't go into much detail on how the encoding works.
Happily, via reddit, I just stumbled across the best explanation of UTF-8 that I have ever seen. It's short and simple and explains everything in a very clear way. If you don't already know all about UTF-8, you should definitely spend 5 minutes with this article.
In conjunction with the above, you might also want to read Xah Lee's excellent post on Emacs and Unicode Tips. It shows you how to get access to these extra characters in Emacs and gives some guidance on integrating UTF-8 into your day-to-day work with Emacs. For that matter, Lee has a Unicode Tutorial page that you might find useful.
Friday, April 15, 2011
Generating Strong Passwords
I'm working on a project that requires several passwords that will be used only occasionally but are not “throw away” passwords. I also need them to be reasonably strong. I could just make some up and save them in an encrypted file, of course, but that would mean just one more file to update and maintain. What I really want is some way to generate then on the fly whenever I need them. The other day I saw a password generator, SHA1_Pass, that does pretty much what I need. What I don't need, though, is a heavy duty app with gui dialog boxes and all that.
So in the DIY/NIH spirit I rolled my own. I want to just type in a name such as “Joe” or “Mary” and get back a strong password. A simple way of doing that is to hash the name with SHA1 and map the result into printable characters. For a little extra security, I concatenated some random characters to the name before I hashed it. Here's the resulting c code:
1: /* 2: * makepw.c -- generate strong passwords given a key phrase 3: * 4: * Compile with: 5: * gcc -Wall -lcrypto -o makepw makepw.c 6: * 7: */ 8: 9: #include <openssl/sha.h> 10: #include <stdio.h> 11: #include <stdlib.h> 12: #include <string.h> 13: #include <stdint.h> 14: 15: int main (int argc, char **argv) 16: { 17: int i; 18: int j; 19: uint32_t wd; 20: char xlat[] = "abcdefghijkmnopqrstuvwxyzABCDEFGHIJKLM" 21: "NOPQRSTUVWXYZ023456789.!-$"; 22: char buf[ 256 ] = "Some-Secret-Key"; 23: union 24: { 25: uint32_t s1[ 5 ]; 26: unsigned char md[ 20 ]; 27: } u; 28: 29: if ( argc != 2 ) 30: { 31: puts( "wrong number of arguments" ); 32: exit( 1 ); 33: } 34: strcat( buf, argv[ 1 ] ); 35: SHA1( (unsigned char *)buf, strlen( buf ), u.md ); 36: for ( i = 0; i < 2; i++ ) 37: { 38: wd = u.s1[ i ]; 39: for ( j = 0; j < 5; j++ ) 40: { 41: putchar( xlat[ wd & 0x3f ] ); 42: wd >>= 6; 43: } 44: } 45: exit( 0 ); 46: }
As you can see, the code is straightforward. The random characters are
already sitting in buf so I just concatenate the input into buf
and call SHA1 to hash the result (lines 34–35). In lines 36–44, I
translate the result into printable characters 6 bits at a time using
xlat and output each character as it's produced. The upper 2 bits of
each word are discarded. The astute reader will notice that the union
introduces an endian issue so if you are going to run this on machines
with different architectures you will have to compensate for that. An
easy way is to replace line 38 with
wd = htonl( u.sl[ i ] );
Also notice that there's a buffer overflow vulnerability because the size of the input isn't checked but this is just a quick hack for my own use so I kept it simple.
If you need more (or less) characters in the password, just adjust the i for loop end count—you get 5 characters for each time through the loop.
When I run makepw with input jcs I get
WRQgWEN-2Z
This works well for me but if you want to do something like this you
may want to replace the Some-Secret-Key in line 22 with a key that
you enter instead. Then you would call it as
makepw secret-key jcs
That provides a more secure application at the expense of having to remember and enter a master key.
On the other hand, you could make it more like SHA1_Pass and not worry about a secret key at all. Instead of entering just a name like “Joe” or “Yahoo!” you would enter some random phrase like “My sister Mary's password for Yahoo!”.
We can refine this a little further. One nice thing about SHA1_Pass is
that it puts the password into the clip board for you so that all you
have to do is paste it into wherever you need it. I'm too lazy to
figure out how to do that programmatically and since this is running
on a Mac I'd probably have to use Objective-C. Fortunately, there's
an easier way. I just wrote a tiny script that pipes the password
into pbcopy, an Apple utility that copies its input to the paste
buffer. X users can use the xclip utility instead.
#! /bin/bash makepw $1 | pbcopy
Now just name this script make-pw, make it executable, and put it in
your execution path and you're good to go. If you're a Mac user, you
can use Automator to turn it into a service but if you're going to do
that you might as well use (the free) SHA1_Pass.
A final note: The above code was run as a Babel code block and
directly generated the resulting password. The #+begin_src line is
#+begin_src c -n :flags -lcrypto :cmdline jcs :exports both
The more I use Babel, the more I like it.
Wednesday, April 13, 2011
The Setup
The other day I got a pointer from Hacker News to an interview with Russ Cox on The Setup. Russ is always interesting and I really enjoyed the interview. Then I made the mistake of clicking on the Archives link and discovered many, many more. It's an excellent black hole for any spare (or not so spare) cycles that you may have. I've already wasted half a day on it.
Each interview asks 4 questions
- Who are you and what do you do?
- What hardware are you using?
- What software are you using?
- What would be your dream setup?
That doesn't sound too promising but it turns out that those questions generate some pretty interesting interviews. I find it fascinating to hear what tools and hardware people are using and why. After you read a few of the interviews, the contrasts between the answers become another interesting aspect.
Many of the interviewees are software engineers as you would expect but there are all sorts of people represented: artists, photographers, scientists, writers, designers, and many others.
It's definitely worth a look but be warned: it can be addicting.
Tuesday, April 12, 2011
Org-mode and LaTeX
Speaking of Org-mode, which I seem to be doing frequently lately, the indispensable Emacs-Fu has a very nice post on producing PDF documents with Org-mode and LaTeX. Org-mode has always exported its documents to LaTeX (at least as long as I've used it) so this isn't anything new but djcb tells us how to change the fonts a bit so that your documents don't look like every other LaTeX document in the known universe.
That sameness in document look and feel is one of the reasons that I prefer to do my writing with Groff, but take a look at the sample document that djcb produces and see if you don't agree that it looks very nice. As usual, it's hard to read Emacs-Fu without learning something useful.
Monday, April 11, 2011
Using Scheme with Babel
As I mentioned in my Blogging and Babel post, Babel supports many languages that produce things other than pictures. Naturally, I wanted to try it out with Scheme. Here's a toy problem that demonstrates some of the things you can do.
Suppose we have some input arguments in a table
| 1 | 2 | 3 | 4 | 5 |
and we want to calculate the values of various functions of those arguments. We start with the definition of the input table and a Scheme source code block:
#+tblname: input
|1|2|3|4|5|
#+source: func-tab
#+begin_src scheme :var args=input :exports results
(define fib
(lambda (n)
(let fs ((n n) (a 0) (b 1))
(if (zero? n)
a
(fs (1- n) b (+ a b))))))
(map (lambda (n) (list n (* n n) (expt 2 n) (fib n))) (car args))
#+end_src
Babel delivers tables to Scheme as a list of rows so the input to the
code block is ((1 2 3 4 5)). Likewise, if we want a table as output
we should return a list of rows. That should help you understand what
the code is doing. As you can see, the map produces a list of rows
where each row is (n n2 2n fibn). All of the functions except fib
are built in, but I included fib to show that you can define
functions in the code block if you need to.
Notice that we named the input table with the #+tblname: input line
just before the table. Similarly, we named the code block with the
#+source: func-tab line; we'll use that name a bit later.
When we run the func-tab code block by typing C-c C-c with the
point in the block, we get the output table:
| 1 | 1 | 2 | 1 |
| 2 | 4 | 4 | 1 |
| 3 | 9 | 8 | 2 |
| 4 | 16 | 16 | 3 |
| 5 | 25 | 32 | 5 |
The table gives the correct results but suffers from the fact that it
doesn't have a heading telling what each column is. We can fix that by
pushing the list ("n" "n^2" "2^n" "fib_n") onto the front of the
result of the map function in the func-tab code block but then we
end up with
| n | n2 | 2n | fibn |
| 1 | 1 | 2 | 1 |
| 2 | 4 | 4 | 1 |
| 3 | 9 | 8 | 2 |
| 4 | 16 | 16 | 3 |
| 5 | 25 | 32 | 5 |
which is better but still not what we want. The problem is that there
is no hline under the headings so when we export the table to html
no <th> tag is generated and we can't use CSS to format a nice looking
table. What we want should look like
| n | n^2 | 2^n | fib_n | |---+-----+-----+-------| | 1 | 1 | 2 | 1 | | 2 | 4 | 4 | 1 | | 3 | 9 | 8 | 2 | | 4 | 16 | 16 | 3 | | 5 | 25 | 32 | 5 |
in Emacs. There's no documentation on how to do that but by trawling
through the Org-mode mailing list I found some hints. At least in
elisp and Scheme you can represent the hline by including the symbol
hline as a row where you want it to appear. Thus we want to push
'("n" "n^2" "2^n" "fib_n") 'hline
onto the front of the result of the map in the func-tab block. We
could do that by adding the code to the func-tab block but I want to
demonstrate something else instead. In general, if we want to post
process output from a block, we can merely call the block from our
post processing code—that's why we named the func-tab block.
In our case we merely want to push a couple of new rows onto the
result of the func-tab block but we could do any processing at
all. To see how that works, we define a new block to do the
processing:
#+begin_src scheme :var tab=func-tab :exports results
(define cons2
(lambda (a b c)
(cons a (cons b c))))
(cons2 '("n" "n^2" "2^n" "fib_n") 'hline tab)
#+end_src
Notice how we set our input, tab, to be func-tab which causes this
block to use the output of the func-tab block. Now the neat part is
that when we get ready to export to HTML we evaluate only this last
block. This, in turn, will cause the evaluation of func-tab but no
intermediate table will be produced so we get only the final desired
result. If for some reason we want the intermediate results too, we
merely evaluate the func-tab block directly.
Another nice feature of this method is that the blocks can be written
in different languages. In fact, the final code block was written in
elisp until I discovered that the same hline trick worked in Scheme.
When we evaluate the last block and export to HTML we get our final result. I've added at little CSS sugar to show how we can improve the output when we have an actual <th> … </th> heading.
| n | n2 | 2n | fibn |
|---|---|---|---|
| 1 | 1 | 2 | 1 |
| 2 | 4 | 4 | 1 |
| 3 | 9 | 8 | 2 |
| 4 | 16 | 16 | 3 |
| 5 | 25 | 32 | 5 |
Sunday, April 10, 2011
Groklaw Calls It Quits
Yesterday, PJ announced that she will stop publishing new articles on May 16, Groklaw's eighth anniversary. It's hard to overstate the importance and impact that Groklaw had on the SCO case. I remember checking in with them several times a day during the hearings—someone from the community always managed to attend and give a first hand report long before anyone else had the story.
And who can forget the hilarity of SCO trying to subpoena PJ but not being able to find her. Then they took to claiming she was an IBM fiction. All the while, PJ and the Groklaw community continued to provide news and analysis that even the trial lawyers found useful and came to rely on.
Farewell, PJ and thanks for the hard work and tremendous service that you did for us all.
Thursday, April 7, 2011
Common Lisp — Myths and Legends
Via Hacker News, I came across this interesting article about Common Lisp. As its name suggests, it discusses the myths that have grown up around Lisp and talks about Lisp's strengths and weaknesses. The article is by LispWorks so it can hardly be said to be a disinterested analysis but it is, I think, an honest and accurate accounting.
The article starts off by characterizing the types of projects for which Lisp is particularly well suited and follows up with some types of projects where Lisp might not make sense. We all know about Paul Graham's WYSIWYG editor for the Yahoo! Store and about ITA's use of Lisp (although ITA isn't mentioned specifically, the article does list airline scheduling among Lisp uses) but did you know that LispWorks is developing a realtime Lisp for use in AT&T's switched virtual circuit capabilities?
The next section is entitled What Does Lisp Offer Me?. It's a good run down of the standard Lisp capabilities, data types, compilers, and standard library. It also includes common (heh) Lisp add ons that, while not in the Common Lisp standard are usually provided.
The final section is entitled Myths About Lisp. This will be familiar ground to any Lisper but might help dispel some misconceptions held by management or engineers who haven't used Lisp.
The article is fairly short and well worth a read.
Sunday, April 3, 2011
Slime for Vim
I just saw this announcement on reddit about getting Slime running on Vim. We've heard it all before, of course, but it looks as if it's real this time. As I've said before, I moved to Emacs after a lifetime of Vim use specifically to get Slime so I should be annoyed but I'm not. Emacs has so much to offer—especially the marvelous Org-mode—that I don't regret the move at all.
Nonetheless, this is great news for Lispers who refuse to give up Vim. Slime makes developing with Lisp much easier and getting that capability without giving up their preferred editor should gladden the hearts of Vim Lispers everywhere.
Tuesday, March 29, 2011
Pictures in Blogger
This is really a note to myself, but others who deliver HTML to Blogger instead of using the Blogger editor my find it useful.
In my Simple Application of Continuations post, I showed a picture of a binary tree. When I first published the post the result looked like the figure on the left. The picture was clipped at the edges and didn't display nicely. After some experimenting, I was able to make the tree look like the picture on the right.

This problem occurs because I write my blog posts in Org-mode, export them to
HTML, and pass that HTML to Blogger rather than use the Blogger editor.
Normally this works well but Blogger doesn't keep embedded pictures with
the post—it puts them in Picasa—so relative links won't work.
Instead, I have to get a link to the picture on Picasa and put it in
the org file so that the generated HTML will have the right link.
Here's how to do this.
- Upload the pictures to Picasa.
- Click on the uploaded picture. This is very important: you don't
want to be looking at the thumbnail that displays after the upload.

- On the right hand side of the screen (in the gray area) you will see
a link that says
Link to this Photo. Click on that link and you should see something similar to what's shown here. If you don't see the check boxes and the size drop down, you didn't click on the thumbnail of the picture you're trying to link to. - From the
Select sizedrop down, pickOriginal size. - Check the
Image only (no link)box. - Copy the link from the
Embed imagebox. - In your org file, place the cursor where you want the picture to
appear and Use
C-c C-lto insert the link.
Saturday, March 26, 2011
My Extensible Calculator
An alternative title for this post might be My Turing Complete Calculator. As I mentioned previously, I was inspired to become a
Lisper after reading Paul Graham's Revenge of the Nerds. In
that essay Graham mentioned that he uses the Lisp REPL as a desktop
calculator. That made a lot of sense to me because I hate using a
mouse to deal with the typical GUI calculator and things like bc are
too hard to remember how to use unless you run them every day.
So I started using the Scheme REPL as a calculator. It was a bit of a
pain to fire up Scheme every time I wanted to make some calculations
but no more so than calling up bc or a GUI calculator. Then one
day, for reasons long forgotten, I needed to calculate the harmonic
series, Hn = 1/1 + 1/2 + 1/3 + … + 1/n, for various values of n.
It suddenly occurred to me that the Scheme REPL was actually an
extensible calculator in that I could add any function I wanted even
if it wasn't built in. Since then, I've accumulated these functions
in a scheme file that gets loaded by a script called calc. Here's
the code for calc.
#! /usr/local/bin/guile -e repl !# (use-modules (ice-9 readline)) (load "/Users/jcs/bin/calc.scm") (activate-readline) (define repl (lambda x ;;to disappear command line arguments (let ((exp (readline "calc--> "))) (if (or (eof-object? exp) (string=? exp "bye")) (format #t "bye\n") (begin (catch #t (lambda () (format #t "~a\n" (eval (read (open-input-string exp)) (interaction-environment)))) (lambda (key . args) (format #t "~s: ~s\n" key args))) (repl))))))
The home grown REPL is there because I first did this under PLT Scheme, which had a REPL function you could call. When I switched to Guile, which doesn't have one, I just rolled my own.
The other part of the calculator is my collection of add-on functions. Here's the help function that lists those functions.
(define help (lambda () (for-each (lambda (f) (display f) (newline)) '("! n: n!" "c->f t: convert celsius to Farenheit" "combo m n: combination of m things n at a time" "coprime? n m: are n and m relatively prime?" "dec->hex d: convert the decimal number d to hexidecimal" "digits n: number of digits in the number n" "f->c t: convert Farenheit to celsius" "factor n: factor the number n" "fibs n: list the first n Fibonacci numbers" "hex->dec h: convert hex number h (#xhhhh) to decinal" "hn n: harmonic sum of n terms" "lg x: an alias for log2" "log2 x: logarithm base 2 of x" "modinv n p: find the mod p inverse of a (p prime)" "next-larger-prime n: find smallest prime >= n" "prime? n: is n prime?" "primes n: list the first n primes" "simpson f a b n: apply Simpson's rule to f between a and b" )) 'Done))
Every time I find myself needing some function that I don't have, I
merely code it up in Scheme and add it to calc.scm.
I can call calc from the command line, of course, but I almost never
do. Instead I start it in an ansi-term under Emacs. I have that
action bound to C-c c so that it's easy to pop into the calculator
whenever I need it. That's especially convenient since, like most
Emacs users, I always have Emacs running.
Friday, March 25, 2011
Blogging and Babel
In my last post, I included a picture of a binary tree. There's
nothing surprising about that, of course. Just fire up graphviz,
say, and in just a few lines you have a png image of your tree. What is
surprising is that everything was done in the org file for that post.
Here is the relevant part of the previous post's org file
#+BEGIN_SRC dot :file tree.png :cmdline -Kdot -Tpng
graph G {
size="2,3";
edge [dir=none, style=line];
node [shape=circle];
5 -- 4;
5 -- 3;
4 -- 9;
3 -- 1;
4 -- 8;
3 -- 6;
}
#+END_SRC
When I put the point inside the block between the #+BEGIN_SRC and the #+END_SRC and typed C-c C-c the code was executed producing the tree

dot produced, of course, and if I type C-c C-x
C-v, the picture is toggled off and the link to the file is revealed.
#+results file:tree.png
When the org file is exported to HTML, the picture is replaced by an <img …> tag.
All this is made possible by Eric Schulte's and Dan Davison's Org-babel, which is now part of the Org-mode distribution. You can find complete documentation for Babel in the Org Manual and there's a nice tutorial at the Worg page.
Babel supports a number of languages as shown on the languages page of the Babel documentation. For example, you can use ditaa to turn ASCII art into nicely rendered diagrams. This
#+BEGIN_SRC ditaa :file tunnel.png :cmdline -r -s 0.65
+---------+ +---------+
| | | |
| Host 1 +<----+ +------->+ Host 3 |
| cBLU | | | | cYEL |
+---------+ | | +---------+
| |
| |
| +--------+ +--------+ |
+---->+ | | +<--+
| GW 1 +<--=--->+ GW 2 |
+---->+ cRED | | cRED +<--+
| +--------+ +--------+ |
| |
| |
+---------+ | | +---------+
| | | | | |
| Host 2 +<----+ +------->+ Host 4 |
| cBLU | | cYEL |
+---------+ +---------+
#+END_SRC
results in this

Finally, here's an example of using gnuplot with Babel. Given this table
| Year | Posts |
|---|---|
| 2009 | 39 |
| 2010 | 10 |
| 2011 | 9 |
and these gnuplot commands
#+BEGIN_SRC gnuplot :var data=posts :file bar-chart.png set size .5, 1 set boxwidth .5 relative set xtics 2008,1,2012 set style fill solid 1.0 plot data using 1:2 with boxes title 'Posts by Year' #+END_SRC
We end up with

All of these examples produced pictures but Babel supports 29 languages including C, Scheme, elisp, Python, Ruby, and many others that do general computation rather than producing graphics. This is perfect for research because all the data, processing code, and final paper can be kept in a single file—the ultimate example of reproducible research.
Monday, March 21, 2011
A Simple Application of Continuations
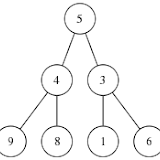
Beginning Scheme programmers—and, indeed, even those with more experience—often have difficulty with continuations. It can be hard to get your head around the concept of continuations. Because they are so powerful and flexible, it sometimes seems as if every use must involve some heavy duty technique.
Here is a simple example that shows how to perform a return from deep
within a series of recursive calls. Given a binary tree, such as that
below, we want to write a function that will return the path from the
root to any specified node in the tree. If the node is not found, the
function should return #f.
(value (left-subtree) (right-subtree))
Thus our sample tree is represented as
(define tr '(5 (4 (9 () ()) (8 () ())) (3 (1 () ()) (6 () ()))))
We will use the standard depth first search technique of recursing
down the left subtree and then the right subtree looking for the desired
node. When we find it, we would like to return the result
immediately. We could do this by having our search routine pass back
the path or #f at each call and then act accordingly, but the logic of
the function then becomes more complicated. Instead we use call/cc
to just return immediately.
1: ;; Return the path from the root of tree to the specified vertex 2: ;; Each vertex has the form (value (left-substree) (right-subtree)) 3: (define dfs 4: (lambda (tree vertex) 5: (letrec ((dfs1 (lambda (tree path ret) 6: (unless (null? tree) 7: (let* ((value (car tree)) 8: (new-path (cons value path))) 9: (if (= value vertex) 10: (ret (reverse new-path))) 11: (dfs1 (cadr tree) new-path ret) 12: (dfs1 (caddr tree) new-path ret)))))) 13: (call/cc 14: (lambda (ret) 15: (dfs1 tree '() ret) 16: #f) ; lambda returns here 17: ) ; call/cc returns here 18: )))
All the work is done in the dfs1 letrec. We either find the correct
node and call the ret function (actually, ret is a continuation)
to return the path (lines 9–10) or we recurse down the left and right
subtrees (lines 11–12).
The continuation is created by the call/cc on line 13. It takes a
single argument, which must be a function of a single variable. In
our case, the function is the lambda function on lines 14–16. The
call/cc passes the continuation to its function argument as the
function's single argument. If the node isn't in the tree, dfs1
will return normally and the call/cc will return #f. If the node
is found, calling the continuation causes control to pass to the end
of the call/cc at line 17. I've abused the formatting a little so
that the extent of the lambda function and the call/cc are
clearer.
This example barely hints at the power of continuations but it does show that they can be used to solve everyday problems in an easy and natural way.
Update: Fixed typos and import of picture
Friday, March 18, 2011
The Secret of Paredit
As I mentioned previously, I celebrated the arrival of Guile 2.0 by installing Geiser. At the same time I installed Paredit. "It's fabulous;" "It's awesome;" "No lisper, regardless of preferred dialect, should even think of editing without it," they said. With praise like that, who was I to refuse? Except that I found it really hard to use. Entering code was easy and it was nice how it kept all the parentheses and quotes balanced. The problem was with making changes.
I'd start with code like
(sis) (boom) (bah!)
then suddenly realize that I don't want to execute that code unless
do_cheers is true. I'd need to edit the code to be
(when (do_cheers) (sis) (boom) (bah!))
How to do that? First, I'd do what I always do: I'd put the cursor in
front of (sis) and type ( but I'd end up with
()(sis) (boom) (bah!)
Not what I wanted. I'd check the cheat sheet and discover M-(. That
sounded like just what I needed but I'd end up with
(when (do_cheers) (sis)) (boom) (bah!)
If I tried to delete that last parenthesis on the second line, the cursor would just skip over it. Finally, I'd just toggle off paredit-mode and fix things up by hand.
By now you're thinking, "Geez, what a luser! Use slurpage already." I
did see that on the cheat sheet but I didn't really focus on it
because I read it as barfage and snarfage and to me and my coevals,
snarf & barf has the specific meaning of cut and paste and that,
obviously, was not what I was looking for. Eventually, I went looking
on the web and found this very helpful post by Aaron Feng that showed
me what to do: just put my cursor in front of (sis), type (when (do_cheers), and then C-) three times to suck the three forms into
the when form. Simple when you know the secret.
I also found this informative slide show that discusses many of the features of Paredit not on the cheat sheet. It turns out, for example, that you can kill a single parenthesis.
The take away from this post is that you should learn about slurpage and barfage if you're going to use Paredit. It makes correcting your code easy and using Paredit a pleasure instead of a chore.
Monday, March 14, 2011
Dired and FTP
I maintain a Web site for our homeowners association. Mostly, this involves updating the monthly board meeting minutes, adding a pointer to them on the home page, and updating the minutes archive page. All of these pages, like this blog, are created in Emacs Org Mode and exported to HTML.
My normal procedure was to make the necessary changes to the .org files, export them to HTML, switch to a bash buffer, and call FTP at the command line to transfer the files to the hosting provider. I may or may not have remembered to clean up the HTML files and buffers when I finished. This was easy enough and only happened once a month so I never worried about whether there was a better way.
Recently, I was browsing around in Xah Lee's wonderful Emacs Tutorial and came across a page on using the shell in Emacs. On that page he mentions that you can FTP files directly from dired: just mark the files you want to transfer, press C (for copy) and when dired asks you for the destination type something like
/ftp:your-login-name@ftp-server-name:/your-directory
Thus I type something like
/ftp:jcs@hosting_service.com:/home-owners-association
Notice that second colon; you'll get a different result if you omit it.
The nice thing about this is that I'm still in the dired buffer with those files still marked so I can just type D to delete them and Emacs asks me if I want the associated buffers deleted too. I type y and all the files and buffers are cleaned up.
I'm sure I'm the last Emacs user on earth to discover all this but it's a nice way of doing that sort of thing. Anyone who does a lot a transferring of files between computers will find it a real time saver. You can use /scp: rather than /ftp: if the host you're transferring to supports it. Actually, Emacs supports several methods as described on this page of the Emacs manual.
Friday, March 11, 2011
Emacs 23.3 has been released.
Doubtless there are binaries available but I prefer to build my own. For Mac users, it's very easy to build right from the sources. First go to the Gnu Emacs Website and retrieve the tarball from Gnu.org or one of the mirrors. Untar it into a working directory and run
./configure --with-ns make install
Then just move nextstep/Emacs.app to the applications folder. To be
safe, you can rename your old emacs first so that you'll have a backup
in case something went wrong with the build.
Blog Theme Tweaking
Oh, look! The Irreal blog has a new theme. Mostly, the change is about getting a little more width for code display. I liked the look of the old theme but the text area for posts was pretty narrow and I got a lot of wrapped lines for the code snippets. The new themes allow a bit more control over such matters, so I changed. Now if I could just get
pre { overflow: auto; ... }
to work everything would be fine.
I'll continue to make small tweaks as I go about personalizing the blog so don't be surprised by additional changes.
Thursday, March 10, 2011
Building Guile 2.0 on the Mac
Introduction
Guile 2.0 was just released in February so neither Fink nor MacPorts have support for it yet. There's no reason to wait, though. It's easy to build Guile from the source distribution. The only problem is that Mac OS X is missing several of the libraries that Guile needs, so they must be compiled and installed first.
In the step-by-step directions below, I have you rerun configure
after each step rather than trying to compile and install all the
libraries first. That's because your system may have fewer or more
missing libraries than mine and rerunning configure will tell you what
you need to do next.
Note that you'll need to be root or use sudo when running make install.
Step-by-step instructions
- Go to the Gnu Guile Web site and download the latest stable release (2.0.0 as of this writing).
-
Untar the source into the directory where Guile will live, change
into that directory and run
configure. Unless you have a current Gnu multiple precision library installed,configurewill return an error saying:Gnu MP 4.1 or greater not found, see README
-
If you don't get this error, you already have Gnu MP installed; go on
to step 4.
a. Otherwise, retrieve Gnu MP from the GMP Web site. I used the latest stable release, GMP 4.3.2 but there is also a “performance release,” GMP 5.0.1.
b. Run
configurewith the build option:./configure --build=x86_64-apple-darwin10
If you don't specify the
buildoption, the MP library will be built for a generic x86 system and the Guileconfigurescript will fail again with the same error. Ifx86_64-apple-darwin10does not describe your system, check the Guileconfig.logfile to see what it's expecting.c. Run
make check. This will exercise the library and make sure everything was built correctly.d. Run
make install -
Change back to the Guile directory and rerun
configure. The next error will tell you the next missing library. I gotconfigure: error: GNU libunistring is required, please install it.
a. Retrieve
libunistringfrom the libunistring Web site and untar it into a working directory.b. Do the usual
configure/make/make installdance to make and install the library. -
Return to the Guile directory and rerun
configure. This timeconfigurewill complain about a missingpkg-configscript. If you don't get this error go on to step 6.a. Retrieve
pkg-scriptfrom the pkg-config Wiki.b. Untar it into a working directory and run
configure/make/make install. -
Return to the Guile directory and rerun configure. This time
configurewill complain about a missinglibffi. If you did not get this error, go on to step 7.a. Retrieve the library from the libffi Web site.
b. Untar the library into a working directory and run
configure/make/make install. -
Return to the Guile directory and rerun configure. The
configurescript will complain about a missing BDW-gc library.a. Go to http://www.hpl.hp.com/personal/Hans_Boehm/gc/gc_source/ and down load the source for Version 7.1. Note that the stable version does not compile on the Mac.
b. Untar the source into a working directory and do the usual
configure/make/make check/make install. At some point (either during themakeor themake checkyou might get an error complaining that theucontextroutines are deprecated and that you need to specify _XOPEN_SOURCE. I did this by editing the source formach_dep.cand including the statement#define _XOPEN_SOURCE
right before the
#include <ucontext.h>
-
Return to the Guile directory and rerun
configure. This timeconfigureshould finish normally and you can try compiling Guile. If you get an error about the missing symbol_rl_get_keymap_name, you will need to go to the readline library Web page and get the latest version of the library. Before you build the library, delete or rename thelibreadlinethat is in/usr/lib. That version of the library is the BSD version supplied by Apple and is no longer compatible. Then build and install the newlibreadlinewith the usualconfigure/make/make install. Return to the Guile directory and runmake clean. Then rerun themake. If you don't run themake cleanGuile may sigfault when you try to run it. Check out your build by runningmake checkand then do themake install. At this point you should have a working version of Guile 2.0.
Saturday, March 5, 2011
Geiser
Having installed Guile 2.0, I was finally able to try out Geiser. For those who came in late, Geiser is an Emacs mode that provides a Slime-like IDE for Scheme. I've been yearning for something like Geiser for a long time. As I explained in Dragged kicking and screaming to Emacs (Pt. 1) (Pt. 2), I moved from being a lifelong Vi user to Emacs specifically to have a comfortable Lisp/Scheme hacking environment. Slime fills the bill nicely for CL, but until Geiser there was nothing as nice for Guile, my preferred Scheme dialect.
Here are some of the features of Geiser taken from the on-line documentation:
- Form evaluation in the context of the current file's module
- Macro expansion
- File/module loading and/or compilation
- Namespace-aware identifier completion (including local bindings, names visible in the current module, and module names)
- Autodoc: the echo area shows information about the signature of the procedure/macro around the point automatically
- Jump to definition of identifier at point
- Access to documentation (including docstrings when the implementation supports it)
- Listings of identifiers exported by a given module
- Listings of callers/callees of procedures
- Rudimentary support for debugging (when the REPL provides a debugger [which Guile does, of course —jcs ]) and error navigation
- Support for multiple, simultaneous REPLs
Another useful feature is that Geiser starts automatically as soon as
you enter a scheme buffer. You can then evaluate whatever portion of
the buffer you like and a quick C-c C-z pops you into the
REPL—very nice.
I've just started playing around with Geiser but so far everything
looks well done. The only problem I've found is that Geiser does not
load the .guile file and there isn't any way of making it do so. The
idea is that you should use the .guile-geiser file instead, but that
doesn't work for me. That's presumably because my .guile loads a
reasonably complex environment including my version of autoload
functions. I was able to work around this problem by putting a local copy
of geiser-guile.el in my init.el file after the form loading geiser.
In this copy, I removed the -q switch in the geiser-guile--parameters
function by replacing the line
"-q" "-L" ,(expand-file-name "guile/" geiser-scheme-dir)
with the line
"-L" ,(expand-file-name "guile/" geiser-scheme-dir)
I wrote and submitted a patch to allow the -q switch to be a configuration option, so perhaps the problem will go away in future versions.
If you're a Guile user, Geiser is well worth trying out. I think it's better than anything else that's available for Guile.
Update 2: The newest version of Geiser now supports loading .guile
Wednesday, March 2, 2011
Guile 2.0.0
After 3 years of work, Guile 2.0.0 was released on February 16, 2011. I have it up and running on my iMac and it appears to be an excellent Scheme implementation. It has a new compiler and associated VM that work seamlessly. See the News file for a list of all the new goodies.
The Gentoo port isn't out yet and I don't use any of the Mac package handlers so I had to build it from scratch. That wouldn't be difficult except that many of the necessary libraries are missing on the Mac. I'll write up and post some notes on how to get it running on the Mac. Other systems will be similar but probably easier. If you're willing to wait for the packages, it should be a breeze.
region-or-buffer (revisited)
In Writing Emacs Commands That Work on Regions or the Entire Buffer I
blogged about an Emacs macro (with-region-or-buffer) that I use to
allow my Emacs commands to work on the current region if one exists or
the entire buffer if not. I've been using that macro for some time
now and it works perfectly for me. It probably works perfectly for
almost everyone but there is an edge case: It implicitly assumes that
transient-mark-mode is set. I've always set it explicitly in my
.emacs file and as of Emacs 23 it's on by default. There are
occasions, however, when one might want to have it off (see Fixing the Mark Commands in Transient Mark Mode for some examples and work
arounds in the Mastering Emacs blog).
This came to my attention while I was browsing in Xah Lee's excellent
Emacs Blog. He recommends using the function region-active-p, which
is merely (and transient-mark-mode mark-active). That takes care of
the edge case and for the sake of portability I decided to update
with-region-or-buffer to use it. In the process of doing that
update, however, I discovered that the recommended solution is to use
use-region-p, which asks the additional question of whether the
region is empty and use-empty-active-region is nil. Since there's
no point in acting on an empty region, using this predicate will cause
the action to be applied to the whole buffer instead.
With this in mind, the with-region-or-buffer macro is now
(defmacro with-region-or-buffer (args &rest body) "Execute BODY with BEG and END bound to the beginning and end of the current region if one exists or the current buffer if not. This macro replaces similar code using (interactive \"r\"), which can fail when there is no mark set. \(fn (BEG END) BODY...)" `(let ((,(car args) (if (use-region-p) (region-beginning) (point-min))) (,(cadr args) (if (use-region-p) (region-end) (point-max)))) ,@body))
Subscribe to:
Posts (Atom)